下半月推荐一首最近很火的歌,就不过多介绍了,我们开始吧。
2021年10月16日
Improving the Assessment of Heart Toxicity for All New Drugs Through Translational Regulatory Science
clinical pharmacology & therapeutics 2014 一篇医学类的文章,看标题是确定药物对于心脏毒性的研究,这里的毒性指的就是对于QT间期延长的影响。标题后半部分“Translational Regulatory Science” 我的理解就是作者希望衡量其他指标来说明QT间期并不是衡量药物毒性的唯一标准,所以是转化传统科学。具体来说,作者提出了药物影响ECG主要是由于钠钾钙三种离子通道的阻塞来导致的,而钠和钙主要影响的是心脏的去极化,而钾离子主要影响的是心脏的复极化,所以他们其实对应着心电图的不同阶段,如下图所示:
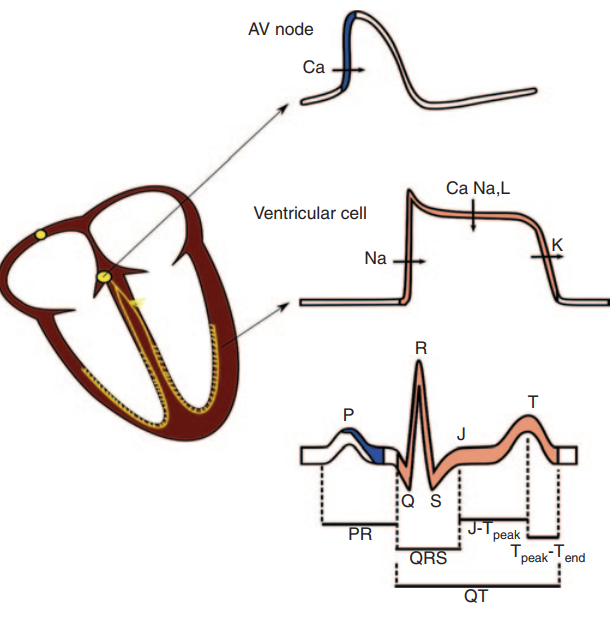
而之前的研究中,只提到了QT间期延长,其实和这三种离子都有关系,作者就怀疑,对于那种阻滞了所有离子通道的药物,他们其实不会进一步引发TdP,而真正危险的是那些主要影响了钾离子的药物,也就是使得hERG通道单独被阻塞的药物。基于这个假设,作者分析了一系列的心电图数据,应该是使用了Physionet的数据集,最终大致证明了他的结论:PR间期延长是钙离子的功劳,而QRS延长是钠离子的功劳,而T区间的延长是钾离子hERG通道的功劳。从我的观点来看,这个医生是在用肉眼完成模式识别,然后训练自己,还是挺厉害的。
在文章的结尾,作者利用两个微观模型对他的猜想做了进一步的验证,他结合了心脏微观电位模型O'Hara Rudy model和宏观模型ECGSIM来模拟钙离子和钾离子通道的变化,然后确实证明了之前的结论:
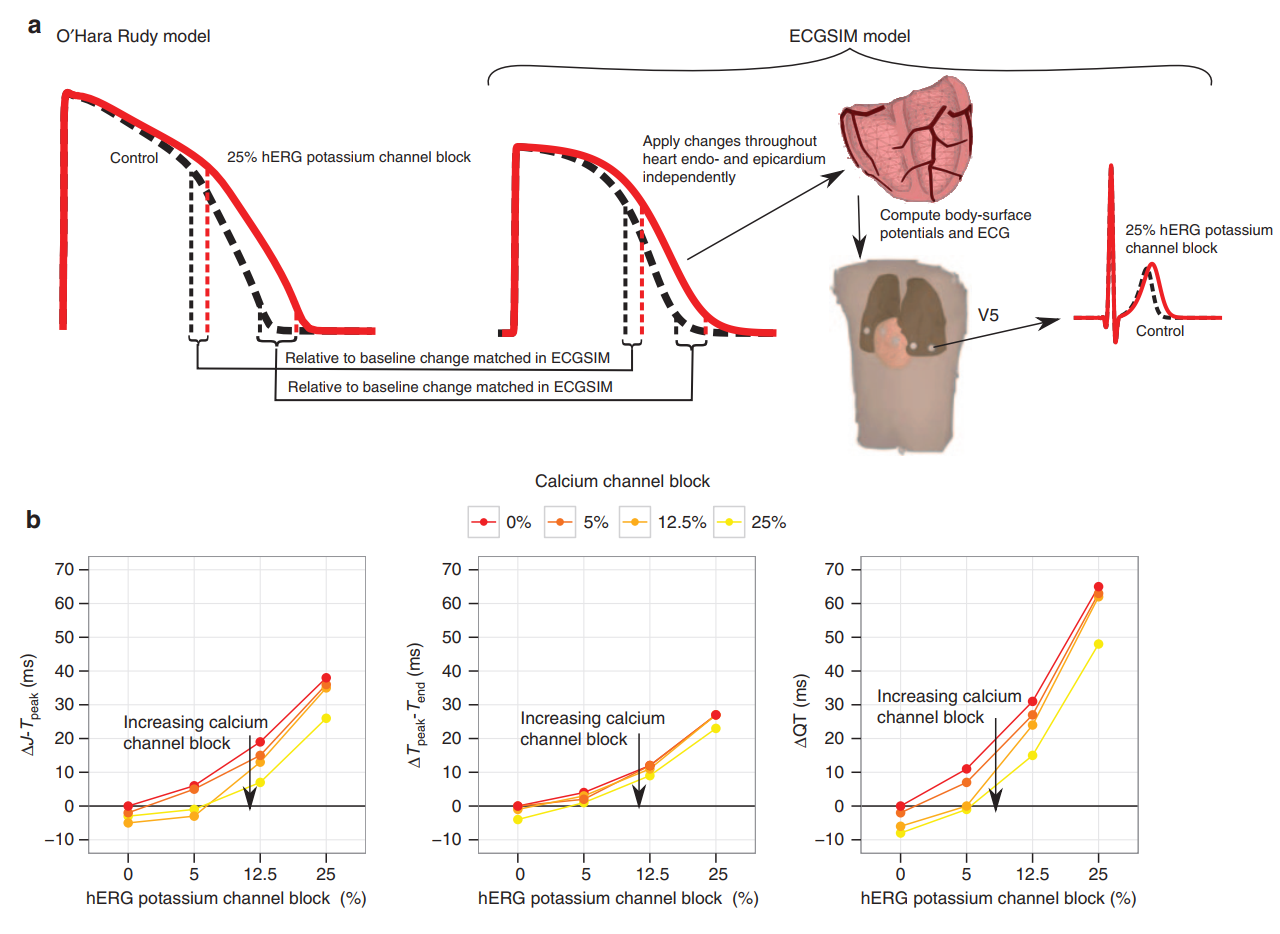
不知道作者具体是怎么在这两个模型里模拟离子通道变化的,文章里语焉不详。但这个软件确实非常厉害,大概在10年前就已经在做了,这是网址:https://www.ecgsim.org/index.php
2021年10月18日
Three-Dimensional Heart Model-Based Screening of Proarrhythmic Potential by in silico Simulation of Action Potential and Electrocardiograms
frontiers in Physiology 2021 翻译为“基于三维心脏模型的动作电位和心电图模拟的前心律失常电位筛选”,基本上与斯坦福的工作有比较相似的地方,都是先建模心脏的离子通道阻滞情况,从而模拟单细胞的动作电位,之后根据动作电位结合有限元模型模拟出真实患者的心电图,从心电图上查看QT间期或者心律失常的变化,这样就将微观与宏观表型联系在一起。作者先获得了所有药物对离子通道阻滞的微观模型,然后根据这个特点得到了在不同血药浓度下的电位变化,这里作者使用了4种模型进行仿真,之后利用有限元模型模拟ECG,基于4种细胞模型就有了4种ECG:
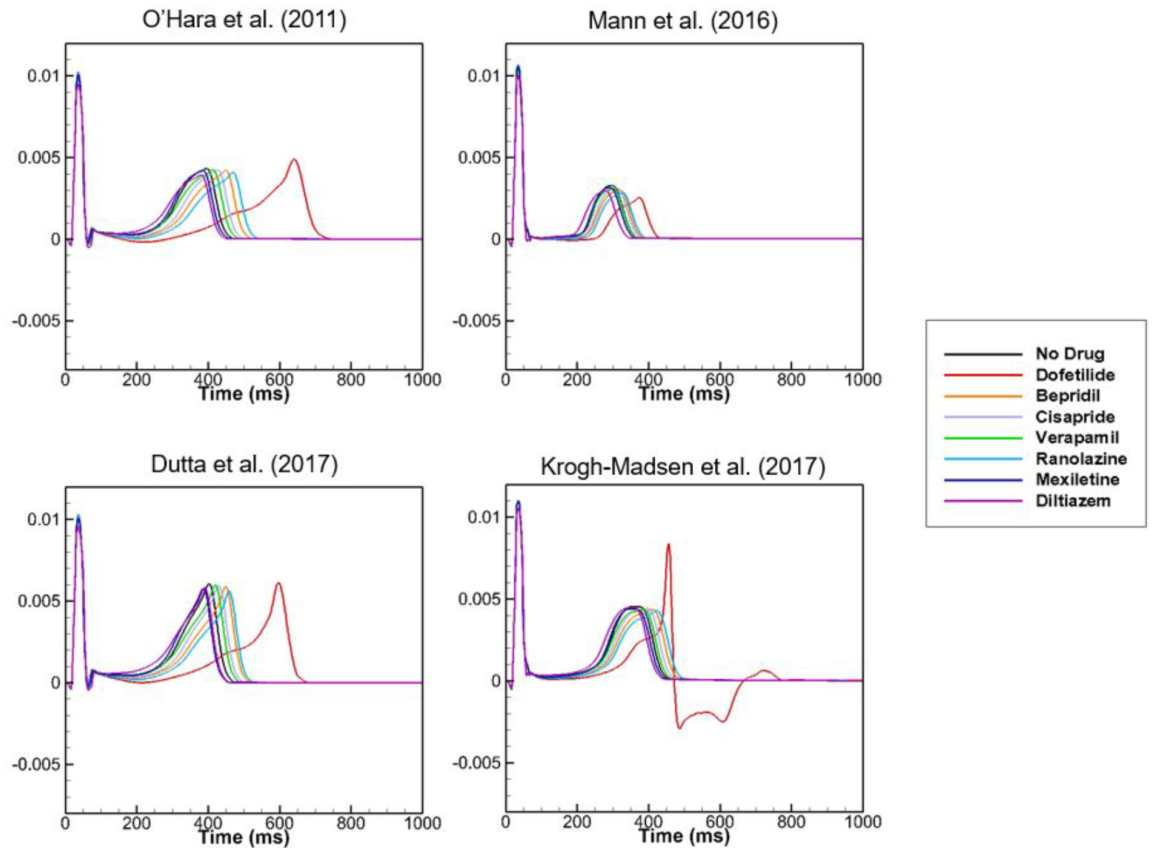
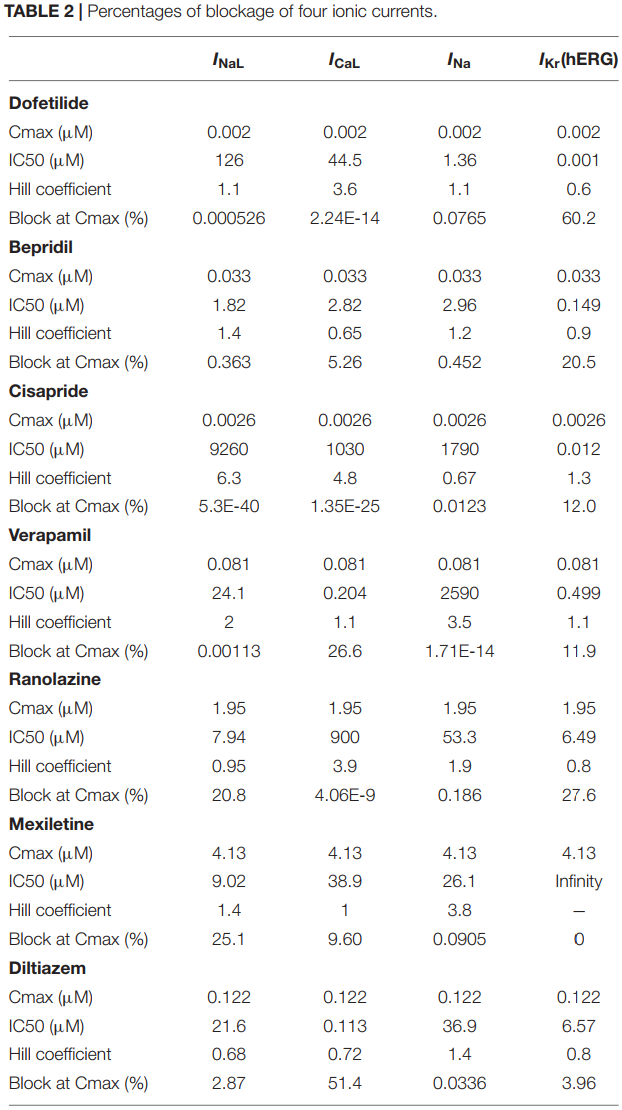
从图上看不同的模型结果还是挺不一致的,作者在讨论中也提到了这样模型还是有一定的局限性。总的来说,从离子通道模拟心电图变化已经有了很多工作,并试图通过这样的方案替代真正的临床试验。
2021年10月19日
Drug-induced QT interval prolongation: mechanisms and clinical management
一篇对于药物引发QT间期延长机理的综述文章。从微观机理,危险因素,致病药物的预防和检测都进行了阐述。作者先回顾了3种常见的先天型LQTS,和之前调研的结果基本一致;然后是对LQTS的测量,基本上使用Bazett公式进行矫正,之后作者介绍了QTc引发TdP在心电图上的显著信号,一般是长短长信号,如下图所示:
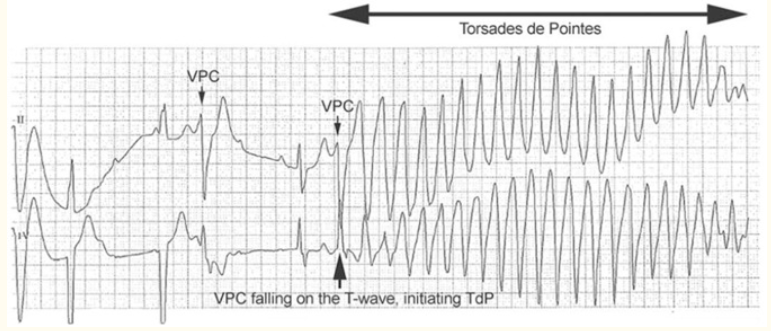
之后作者列出了所有QTc引发TdP的风险因素,除了女性和高龄外,还有一些比较读的的像是利尿剂使用,肝脏功能不全,心动过缓,基因突变和*洋地黄疗法*(还不知道这个是什么)。之后作者回顾了所有能引发TdP的药物列表,和直接从网站上查到的差不多。
现在我倒是觉得可以直接从TdP的识别作为一个入手点。
2021年10月20日
今天主要研究了一下DrugBank的使用,还是挺有意思的。还不清楚这样的Xml信息如何能够转换成知识图谱,可能还是要借助Bio2RDF等标准。比如以胺碘酮作为例子,我们可以得到它这些信息:
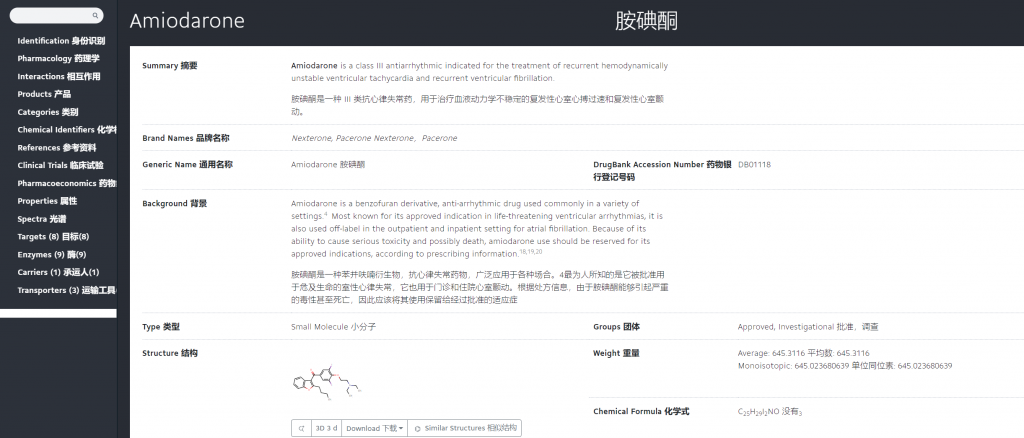
基本上有化学式,他的基本用处与归类,还有他与其他药物的相互作用关系,但这个作用关系目前还只是文字描述,如果能变成归类的信息就更好了。还可以在药理学中学习药物的药效时间,以及查询到相应的临床试验或者微观试验。今天偷个懒,这里有一个很详细的介绍:Drugbank:最强大的综合性药物数据库,收藏 - 知乎 (zhihu.com)
2021年10月24日
Assessment of Multi-Ion Channel Block in a Phase I Randomized Study Design: Results of the CiPA Phase I ECG Biomarker Validation Study
CLINICAL PHARMACOLOGY & THERAPEUTICS 2019 对CIPA的临床试验结果进行解释说明的一篇文章,文章主要还是想证明J-Tpeak是区分离子通道都阻滞和只阻滞hERG药物的生物标志物。在实验里,作者选了Ranolazine, lopinavir/ritonavir, and verapamil作为离子通道banlanced的药物,而选 Chloroquine 一种药物作为非banlanced的药物。作者一共召集了50个人进行临床试验,一个药物10个人,作者记录了他们服药后三天内的心电图变化
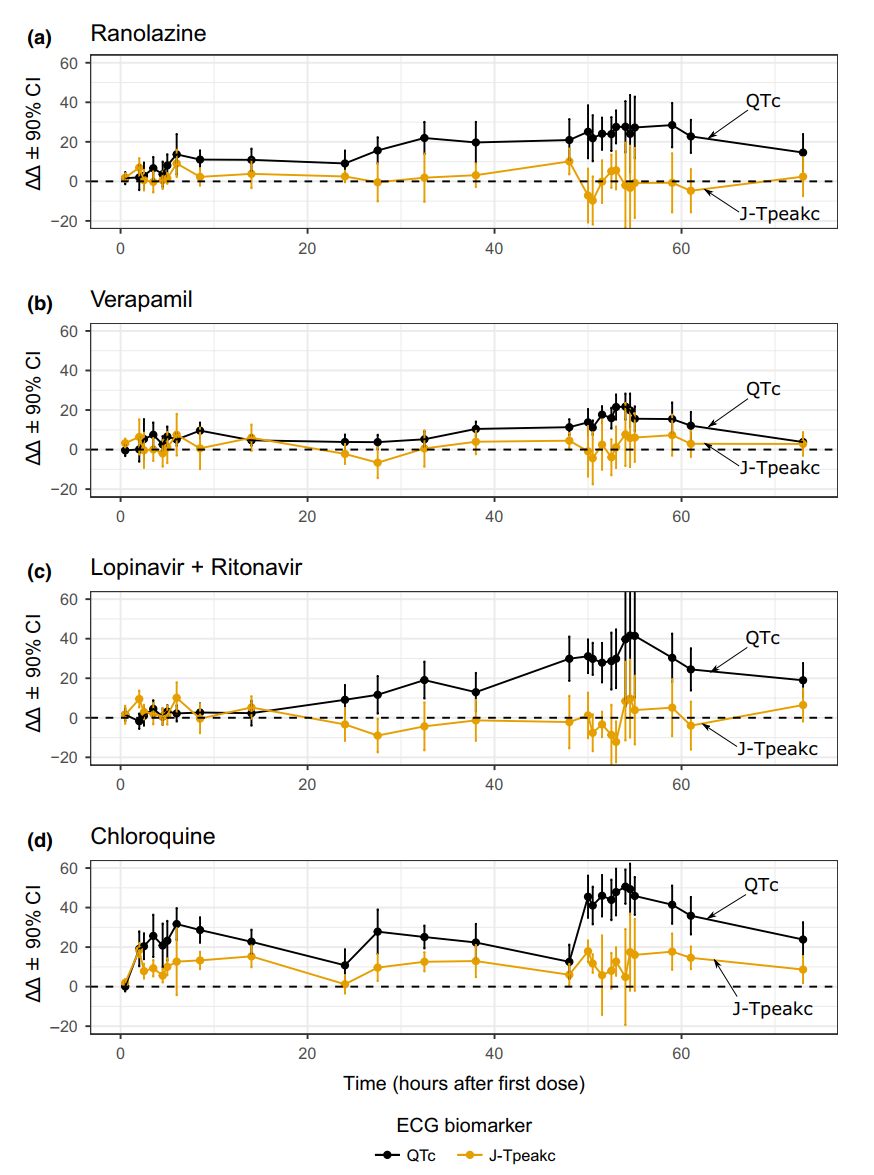
可以看到这些药物基本上都是第一天服药和第三天服药后产生了明显的作用,作者所谓的离子通道平衡的药物并没有引发严重的QTc延长,这说明药物的离子通道属性是影响QT区间的一个很重要的因素。另外作者还探寻了药物浓度和QT区间的关系,但是只有10个对照实验是否能够作为真正的标注还有待考量。
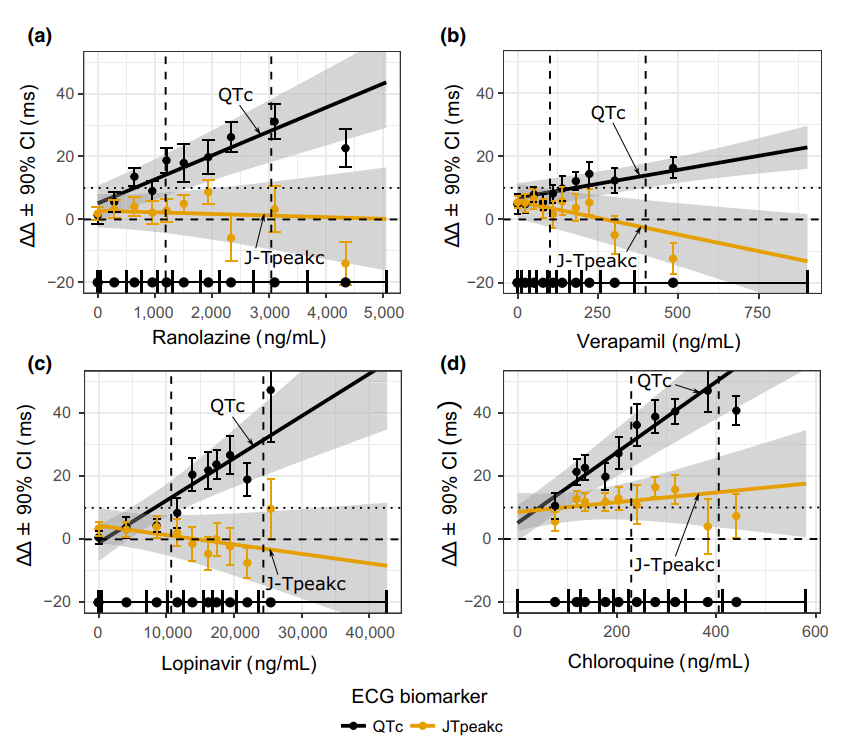
在第二个实验中,作者考虑了diltiazem对dofetilide引起QTc延长的缓解效果,这部分没有仔细看。
下一次要着重关注的是,作者 如何选取了第一天和第三天的时间节点作为查看QT延长标准的,也就是像上图的曲线作者是如何得到的,所谓的90%CI置信区间又是怎么计算的?
另外作者使用的检测QT区间的算式来自于文章Automated algorithm for J-Tpeak and Tpeak-Tend assessment of drug-induced proarrhythmia risk,github地址为https://github.com/FDA/ecglib,不知道和Neuronkit哪个好用。
2021年10月25日
Mechanistic Model-Informed Proarrhythmic Risk Assessment of Drugs: Review of the “CiPA” Initiative and Design of a Prospective Clinical Validation Study
CLINICAL PHARMACOLOGY & THERAPEUTICS 2018 对于整个CiPA项目的回顾,也是对上一篇文章的补充。
在文章中,提供了CIPA计划的整体流程图,具体是1. 从体外实验评估不同药物对钠钙离子以及hERG钾离子通道的阻滞作用,2. 通过实验数据进行计算机仿真模拟得到药物的风险情况,3.对于计算机仿真结果,分别通过IPSC诱导的心肌细胞以及体内临床试验进行结果验证。
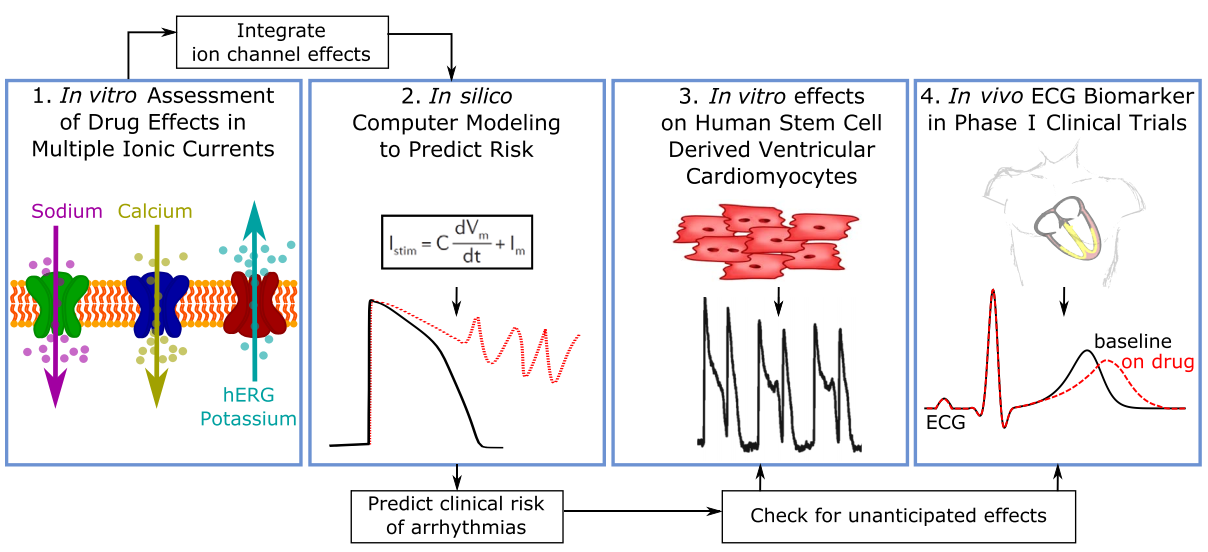
在文章中也可以找到上一篇文章所做的实验设置,这样就可以解释为什么在上一篇文章里,QT总是在某几个时间点上突然延长。

然后作者给出了具体的分析方法,作者首先说明10人为一组记录QT区间的延长情况是足够的,列出了两篇15年的参考文献,然后具体的方法是利用了统计线性混合效果暴露反应模型:
$\Delta ECG ~ time + treatment + concentration + (1 + concentration|subjid)$
其中$\Delta ECG$是QT等区间的变化,concentration是药物浓度,treatment 0为安慰剂,1为药物,time为时间节点,subjid是指具体的人员标识符,所以在模型中(1 + concentration|subjid)就代表了患者特异的模型。
2021年10月26日
Relationship of clinical adverse event reports to models of arrhythmia risk
Journal of Pharmacological and Toxicological Methods 2019 利用FDA公开数据库进行类似于比例研究的工作,作者建立了一个二联表,主要是计算药物A造成不良事件X在所有不良事件X的比例记为事件P,而药物造成非X不良事件在所有非X不良事件的比例记为事件Q,基本思路就是通过事件P和Q来确定药物是否与不良事件X有很强的关系。具体内容没有深入看。
Statistical Learning in Preclinical Drug Proarrhythmic Assessment
Arxiv 2020 看起来很厉害,其实没那么深奥的一篇文章。总得来说,这篇文章通过利用膜片钳电生理实验的数据,以药物每次实验的一次记录提取得到的特征作为输入,通过训练有序的logistics 和RF模型,来区分药物的风险程度,具体来说这两个所谓的有序模型思路都比较简单,公式如下:L,M,H就代表低中高三中风险。说实话我没搞懂为什么这样就是有序的?

再得到概率后,作者进行了 所谓的 stratified bootstrap策略,简单讲就是重复采样样本后再送入模型训练,从而就能够知道模型输出结果的稳定性,这确实算是统计学习理论中的一环。
当然文章中也有要学习的点,具体是如何从相应的电生理学信号中提取出所谓的predictors,也就是要预测的label如何定义,第二个是真的好好学习一下文章的遣词造句,我们在利用尽量少的语言描述留一法验证时,又应该怎么用尽量详细的话语来说明他的作用。
Ordinal Regression
是文章中提到的有序回归的思想,wikipedia的解释如下:
In statistics, ordinal regression (also called "ordinal classification") is a type of regression analysis used for predicting an ordinal variable, i.e. a variable whose value exists on an arbitrary scale where only the relative ordering between different values is significant. It can be considered an intermediate problem between regression and classification.[1][2] Examples of ordinal regression are ordered logit and ordered probit. Ordinal regression turns up often in the social sciences, for example in the modeling of human levels of preference (on a scale from, say, 1–5 for "very poor" through "excellent"), as well as in information retrieval. In machine learning, ordinal regression may also be called ranking learning.[3][a]
顺序回归是一个挺有意思的问题,就是我们在例如预测年龄或者连续变量的问题上,可能由于数据原因或者本身问题的精度原因,我们并不需要做成一对一的回归问题,比如通过照片识别年龄,实际上我们可能只需要知道3年甚至5年的年龄区间就可以了,这样把年龄从0-100分为20份,那么可以是一个经典的多分类问题,但是这里并没有考虑到一个问题:模型预测一个25岁的人为20岁,肯定比预测他为70岁的惩罚更小。因此我们在设计任务的时候,可以设计为质量分布函数,也就是说,之前的任务是预测$f(x)=P(20<x<25)$的可能性大小,但是在Ordinal Regression里,我们考虑$f_{20}(x)=P(x<20),f_{25}(x)=P(x<25),...$等概率,这样,样本输入单个区间的概率就定义为$P(20<x<25)= P(x<25) - P(x<20)$。从直觉上讲,让模型去学习一个人年龄有没有小于25岁,肯定比学习一个人年龄的区间会更加容易。 这部分的理论和性质,还需要进一步的了解。
2021年10月27日
梳理一下有关QT研究的临床实验,一开始最有名的应该是ICHS7B和ICHE14,前者的主要贡献是提到要用hERG基因作为体外研究Ikr离子通道的代理,而后者主要提出要通过QT区间来查看药物在体内影响离子通道的能力。这两个实验的弊端就是灵敏度很高,但是特异度比较低,所以CiPA计划又开始进一步发现更能体现TdP的标注物,但是只有20多种药物经过了验证,主要贡献是将药物区分为所谓的双向阻止和单向阻滞药物, 此外还有RVWA( rabbit ventricular wedge assay )计划在体外测验药物引起TdP的风险,它对28种药物给出了一个标准化后的TdP分数。
昨天文章中还提到了一个指标,C-index,C指数即一致性指数(concordance index),用来评价模型的预测能力。c指数是指所有病人对子中预测结果与实际结果一致的对子所占的比例。
Ordinal Regression Methods: Survey and Experimental Study
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 2016 一篇算法文章,主要讲述的是Ordinal Regression问题的定义和目前的解法,最后还进行了很多实验。今天只看了前半部分。
文章提到了顺序回归与分类相比,隐含了不同类之间的信息,而和回归问题相比,并没有包含任何的度量信息,因此是一个定性分析而不是定量分析。
顺序回归问题和以下几个术语都比较相似:ranking,sorting,multipartite ranking.
对于Ranking来说,是设计一种算法将样本中的某些模式排列成一些给定的顺序标签,而标签数是小于样本数的,所以会出现多个样本属于一个类别的情况。但这个规则只需要保证相对顺序是对的,并不用保证分类正确。文中举的例子是将分类器结果平移一个单位,但是样本之间的顺序仍然是保留的。
对于Sorting问题,是设计一种算法将所有样本进行排序,所以我们不允许出现相同排名,这个和OR的区别很容易识别。
对于multipartite ranking,是指先用分类器将样本分成多类,然后对于每一类中,我们对其中每一类再区分样本的相对前后大小。和OR问题比,属于更升级一步。因为在OR问题里我们只关心把样本回归到相应的类别里,而不关心同一类中样本值的先后顺序。
接下来,作者对OR问题解决算法进行了归类,一共有三种算法:
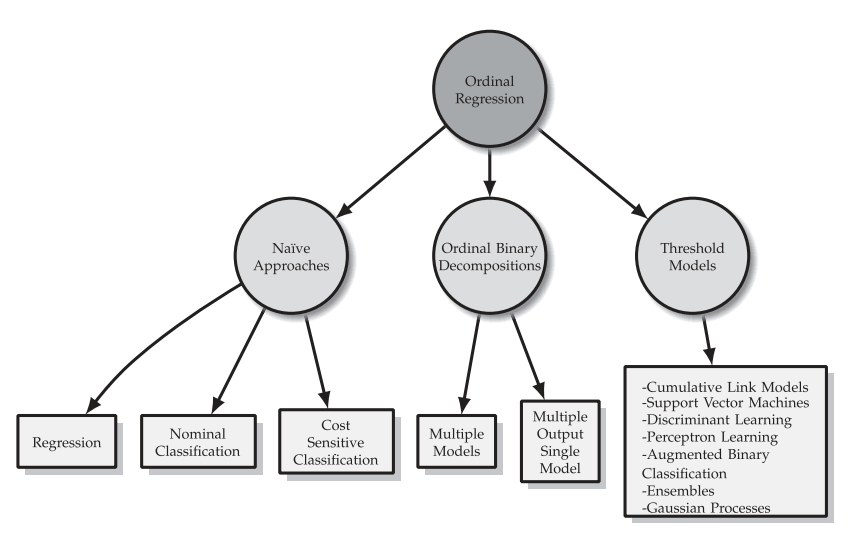
Naive 方法就是指将这个问题建立成为简单的多项分类或者回归问题,最多是添加一些奇怪的权重约束,比如真实标签为1,那么选2的损失就比选5的损失大。
Ordinal Binary Decompositions 则是将问题拆解为许多个二分类的子问题,然后再定义一套将二分类问题进行集合的规则,本质上还是分类问题的延伸。
Threshold model是假定顺序回归问题还是存在一个连续的隐变量,那么顺序回归就是要找到这个连续隐变量上合适的阈值,通过不同阈值的分割,将隐变量划分在某一区间的样本就属于顺序回归的某一类,和上一类其实有点像,但感觉有更多的理论保证。还需要再看看。

文章评论