这是Whirl Paper Flash系列的第二章,针对文章分享的时间感觉还是没有想好,从试运行的结果看,似乎一周的内容已经足够多了,所以我目前准备采用一天更新1-2篇,半月更新整篇文档的方式。话不多说,开始吧。
这次要分享的歌曲是Space Oddity,wiki的介绍如下:
“Space Oddity”(中文:太空怪谈)是大卫·鲍伊写的一首歌。它于1969年7月11日首次以7英寸单曲发行。这是他的第二张录音室专辑《David Bowie (Space Oddity)》的第一曲。它是大卫·鲍伊的标志性歌曲之一,也是他的四首被列入摇滚名人堂的“塑造摇滚的歌曲”(Songs That Shaped Rock and Roll)歌曲之一。
这首歌是关于一位虚构的宇航员小汤姆发射到太空,并在太空飞行期间演唱这首歌。美国的“阿波罗11号”任务将于5天后发射,并将成为此后5天内人类首次载人登月,[2]所述的歌词也已看到讽刺的至今无法载人飞行的英国太空计划。[3]
1969年,这首歌在英国单曲榜上达到了第5名,并获得1970年年度Ivor Novello特别创意奖。[4]; 1973年重新出版后,“Space Oddity”在Billboard榜上达到了第15位,并成为大卫·鲍伊在美国的首支入榜的单曲;在加拿大,它达到了第16位[5];1975年,这首单曲再次发行,成为英国排名第一的单曲。[6]
2013年,这首歌在加拿大宇航员克里斯·哈德菲尔德(Chris Hadfield)的演唱下重新受到欢迎,他在国际空间站上演唱了这首歌,成为第一部在太空中拍摄的音乐录影带。[7]
2016年1月,这首歌曲在鲍伊去世后重新进入世界各地的单曲榜,其中包括成为鲍伊的第一首第一名单曲,成为法国单曲榜的首位。该歌曲在2016年1月12日的iTunes上也排名第三。[8]
2021.10.1
国庆快乐!
走好选择的路,而不是选择好走的路2021.10.2
GANITE: ESTIMATION OF INDIVIDUALIZED TREATMENT EFFECTS USING GENERATIVE ADVERSARIAL
ICLR 2018 这是九月篇总结individual treatment effects文章中提到的文献,也是之前组里分享过的工作。文章主要还是在考虑因果推断问题,即对于现有病人$X$,我们在做了一些治疗$T=t$后,得到了事实结果$Y^{T=t}$,那么我们关注的问题是在平行宇宙的反事实治疗$T=t^\prime$下,病人的结果如何。但是显然问题是我们永远不可能知道反事实是怎么样的,所以文章想到了利用GAN来生成反事实的结果,补全数据集。之后因为患者用药后结果和给药是独立的,所以需要再训练一个ITE block,从患者本身状态出发预测所有的结果。模型的整体框架如下:
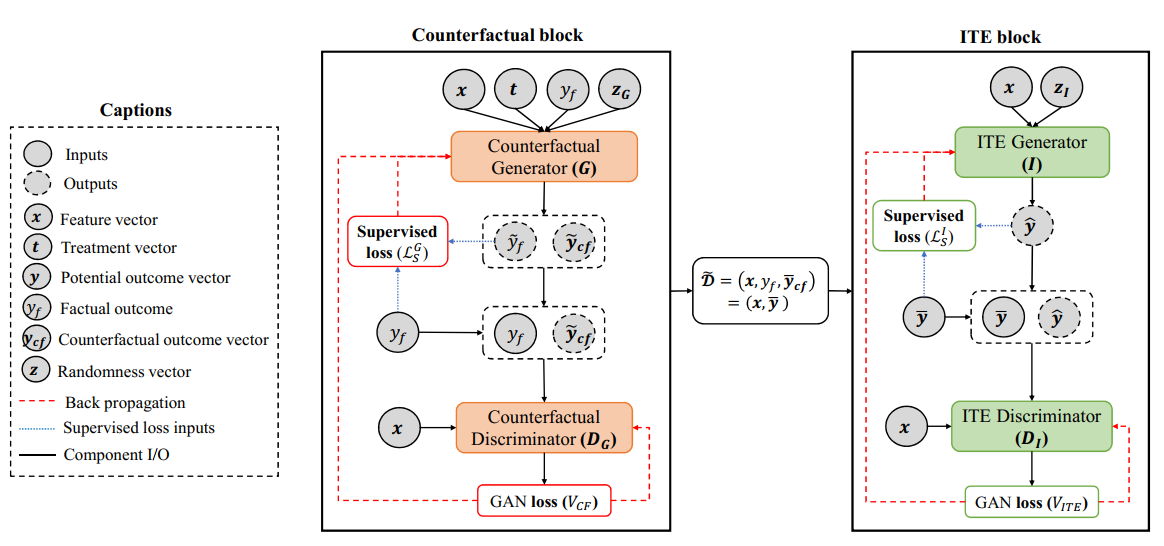
具体的实现细节是先训练左边的GAN,再训练右边的。注意到与之前的GAN不太一样的地方是,普通GAN是区分样本,而这里有点像是生成标签的工作,利用生成的标签与真标签送给Discriminator。最终模型的效果当然是当年的SOTA。此外作者还提供了对比实验:
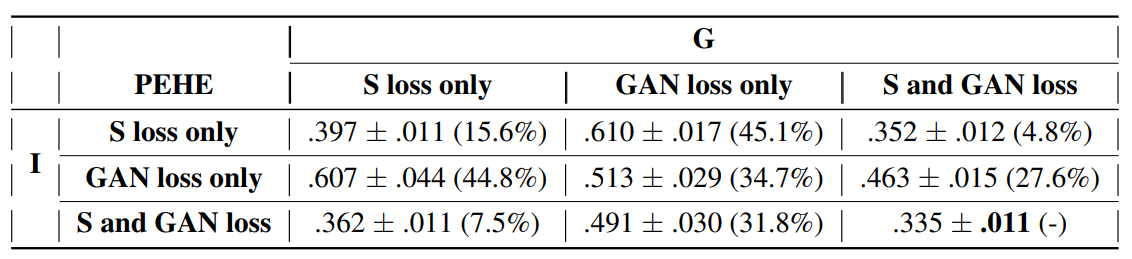
S loss是监督,GAN loss就是生成的loss,可以看到其实在两个GAN都是S loss的情况下,模型的效果0.397也不是很差,反而是只有GAN的时候,学不出来标签的分布。所以有意思的问题是,当我们要预测的标签是样本状态时,这个模型该如何改进呢?
因果推断的入门:讲解相关与因果的关系:因果推断入门(Ⅰ) - 知乎 (zhihu.com)
2021年10月3日
PDD Graph: Bridging Electronic Medical Records and Biomedical Knowledge Graphs via Entity Linking
International Semantic Web Conference (ISWC) 2017 记录一篇之前看过的文章,文章主要想解决的问题是现有的电子病历文本信息与生物医学知识(ICD-9和DrugBank等)存在比较大的GAP,所以他们采用了知识图谱的方式将这两种数据连接在一起,组成了 Patient-Drug-Disease Graph,简称为PDD Graph。项目的地址在http://pdd.wangmengsd.com/index.html 。其中每个病人是一个节点,病人节点连接的是住院情况,而每一次的住院主要链接了患病情况以及用药情况,在这里作者使用了一些工具从医学文本里提取了患病情况,统一了药物名称;以上信息都来自于MIMIC数据本身。之后药物与药物以及药物与疾病的关系都来自于DrugBank的信息,注意到这里药物与疾病的关系本身在MIMIC中也有体现,所以作者规定药物与疾病的关系必须同时在临床数据和医学知识中同时出现。最终的知识图谱如下所示:
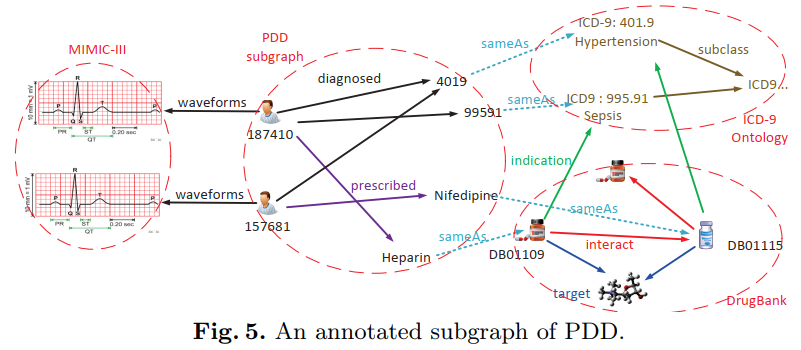
2021年10月4日
Predictive Analytics for Identification of Patients at Risk for QT Interval Prolongation: A Systematic Review
Pharmacotherapy 2018 一篇关于患者QT间期预测风险的综述文章,作者一共找了61篇文献,经过QC后剩下10篇,不得不说还是有点少。这10篇都是通过某些指标和用药情况最终预测患者QT间期是否延长。
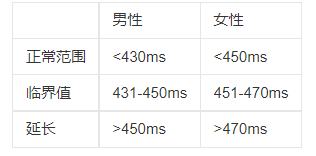
QT间期在正常人心脏中是比较稳定的,99%分位点为470-480ms,而只要大于500ms,就会引起 torsade de pointes (TdP),一种致命的心律失常。 在文章调研的工作中,很多都是收集病人的指标与用药,然后通过队列的分析设定分数,将病人分为不同的风险等级,文章作者用了逻辑回归的方式,定量刻画了QT间期的风险,并应用到了诊所中,文章后段内容主要讲解了这个风险预警系统在实际的诊所中有很多用处。从方法学上,感觉对于QT间期的推演应该还需要更细致的刻画,而不简单是对于风险的预测。
这里附上QTc间期的范围表:
Prediction of Drug-Induced Long QT Syndrome Using Machine Learning Applied to Harmonized Electronic Health Record Data
Journal of Cardiovascular Pharmacology and Therapeutics 2021 利用UC health 医院的格式化EHR数据,一共35639个病人吃了与QT间期有关的药物,而其中4558个人发现QTc>500。之后作者就用这两组数据作为正负样本,利用药物,程序代码,诊断代码,实验室和人口统计数据做预测,使用了多个模型,之后效果最好的是神经网络,高达0.71的ROC,F1为0.4分。文章的重点落在了对正负样本不均衡的处理上,并且数据也没有开源。值得学习的是关于样本的处理,作者删除了QRS间期>120ms的样本,认为这些本身已经有心脏疾病。
2021年10月5日
Deep learning analysis of electrocardiogram for risk prediction of drug-induced arrhythmias and diagnosis of long QT syndrome
ESC 2021 一篇用机器学习(CNN,RF,LR)预测 Torsades de pointes (TdP)尖端扭转型室速过速病的,数据量比较大,文章后半部分还有对 CNN的解释,能发在ESC上我觉得比较重要的一点就是数据量足够多,从模型上看其实没有 什么亮点,输入是一段10秒长的8通道心电图,输出就是预测这个人是否吃了能使QT间期延长的药物/是否有cLQTS疾病。这里cLQTS指的是先天性的长QT间隔综合征,主要是由于基因突变造成的。在实验设计上值得学习的一点是,作者说真正发生cLQTS的人很少,所以他们就让正常人吃药来扩充样本。
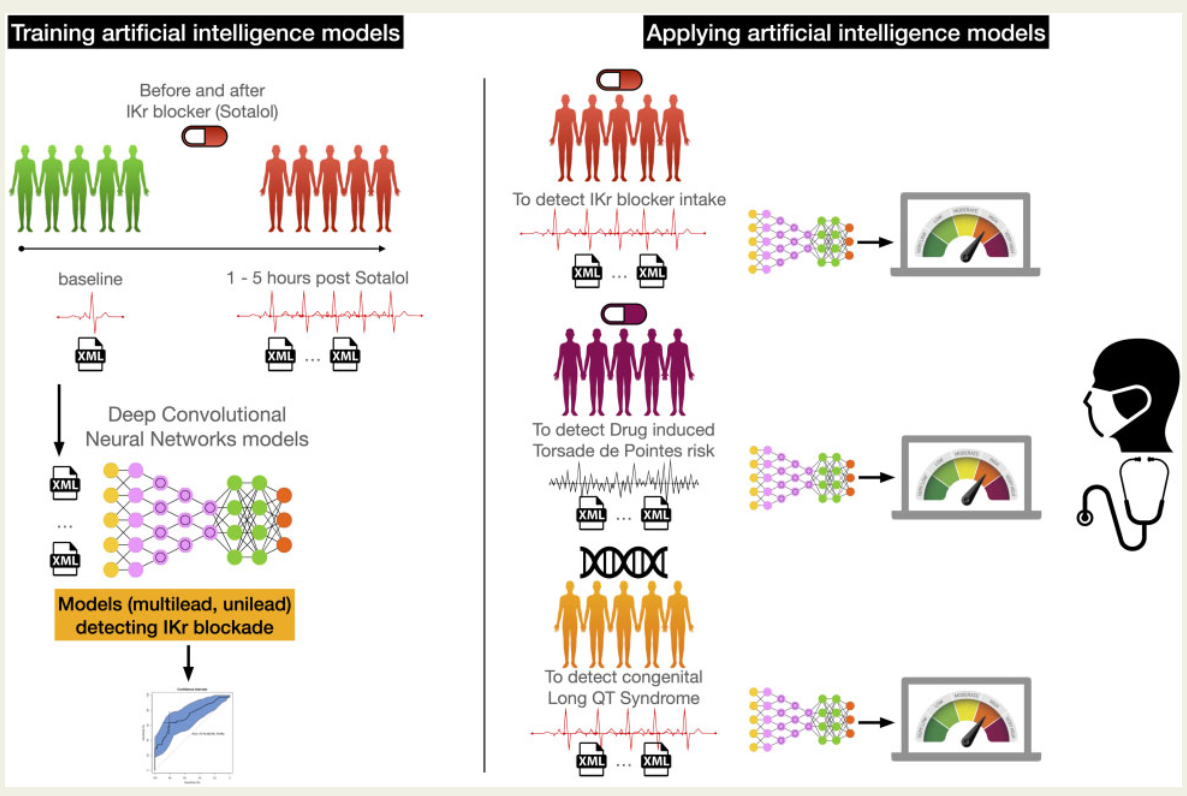
整篇文章强调的重点是端到端,以及数据集,在方法学上可学习的地方不是很多。另外,文章也提到了之前也有人用PhysioNet数据库里的数据做了类似的事情,但是只有42个病人。。。好吧,果然有数据就是牛啊,附上另一篇文章的标题 Noninvasive assessment of dofetilide plasma concentration using a deep learning (neural network) analysis of the surface electrocardiogram: a proof of concept study.
2021年10月6日
Predicting Drug-Induced QT Prolongation Effects Using Multi-View Learning
IEEE TRANSACTIONS ON NANOBIOSCIENCE 2013 看标题以为是衡量患者服药后QT间期影响的,实际上是对药物本身进行分类的工作。作者利用了药物的分子特征描述符作为输入,预测其是否为能够使得QT间期延长的药物。比较有趣的一点是,文章中用到了multiview learning的思想。
什么是multiview learning? 简单说就是我们现在有10000个苹果和香蕉,每个水果都有一些特征,但其中只有1000个有人为的标注,所以我们在这1000个上训练两个分类器A和B:A负责区分红色和黄色,B负责区分圆形和非圆形。注意这里A和B用到的特征是不一样的。接着我们拿A去剩下9000个样本上做测试,找到其中置信度最高的100个样本,把这些样本的放到B的训练集里重新训练B1。B1训练好后,用同样的办法选出在B1中置信度最高的100个样本送到A中去,这样往复迭代,我们就完成了训练,还标记出了剩下的9000个样本。
算法的原理就是,样本存在多个视角(view),在不同的视角下区分程度不同。那我们在A视角可以区分的样本在B视角可能难以区分,但可以刚好用来训练B分类器。由此迭代往复,我们就可以得到最终的结果。这是半监督学习中的一个很常见的思想,看来还是得多读读文献。
说回文章本身,文章在考虑药物是否为QT间期延长药物时,也考虑了他们对于钠钾钙离子通道的影响作用,这个影响作用就是样本的第二个视角B,通过B视角,最终使得对QT间期延长的判断更为相似。
2021年10月07日
Single-cell Transcriptomes Reveal Characteristics of MicroRNA in Gene Expression Noise Reduction
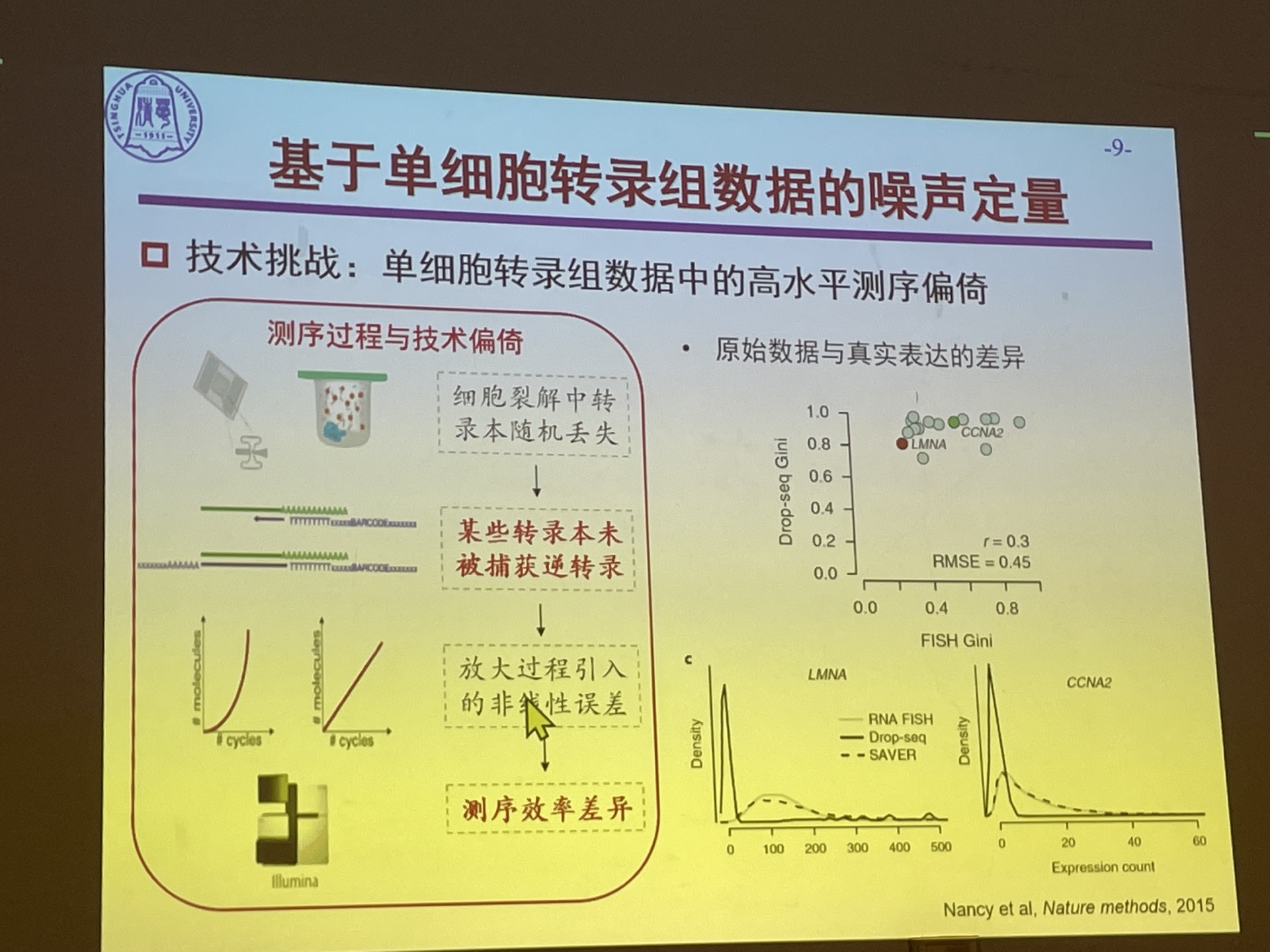
Genomics, Proteomics & Bioinformatics 2021 大实验室里定量单细胞转录组数据中基因噪声定量衡量的模型,基于测序过程进行统计上的建模。先用二项分布模拟转录本捕获的过程,再用泊松分布模拟转录本被测序捕捉到的模型。基于这样的建模,我们可以估计出基因表达中的方差,而方差又可以被拆成固有噪声和测序噪声。之后作者又进一步去除了由于均值带来的噪声的变化。
在具有描绘基因表达固有噪声的能力后,之后发现在有miRNA调控的基因中与普通的基因表达情况不同,所以就对这些基因进行进一步的分析
问题:描述表达噪声的最小单位是什么?是细胞还是基因
PPT讲的过程中值得学习的点:一开始提出一个例子,在讲完整个方法后返回来说明自己的方法可以解决例子的问题。
2021年10月8日
Research of Medical Aided Diagnosis System Based on Temporal Knowledge Graph
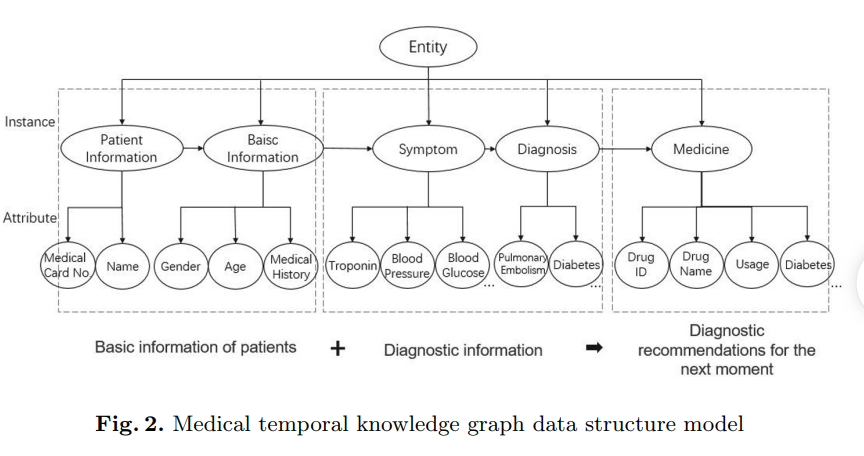
ADMA 2020 看文章标题以为是用到了动态知识图谱的推断,实际上作者对于每个病人构建了能够反应时间序列信息的实例图谱,然后在实例图谱上进行特征的学习和预测,图谱的结构如下所示:
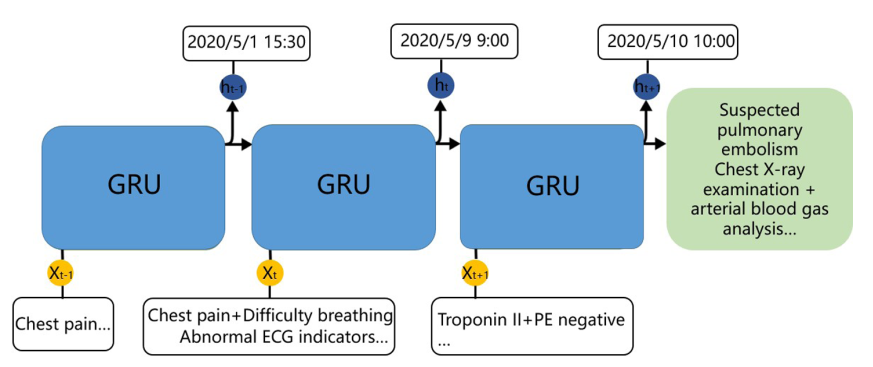
作者的目的也很简单,就是估计病人有无肺塞栓的并发症。而输入就是之前所有的按照序列连接的三元组。对于每个三元组,作者利用了TransR模型计算其embedding,但作者没有说清楚一个三元组是怎么处理成一个向量的,因为按理说TransR模型对于每个关系都有一个映射矩阵,然后再根据映射矩阵都有实体的表示,那么一个三元组至少有3个向量。接着作者利用GRU模型把三元组按照顺序一个个输入,最后去估计下一个时刻病人的状态。模型图如下所示,感觉图里说的有些太牛了,上面的日期和右边的输出也没有解释:
数据集作者用了自己收集的医院数据,并且还有医生对数据做了标定。
2021年10月9日
Detection of drug-induced QT Syndrome from ECG using machine learning techniques
IEEE ICECE 2018 一篇有点像在灌水的文章,看标题以为是从ECG里检测QT区间,但文章里写又是区分哪些药物会引起QT区间的延长。具体来讲,作者从ECG里提取到的特征作为模型的输入,模型的输出是药物的名字,也就意味着是这个药物引起了QT的延长。作者利用了physionet上一个04年的数据,这个数据主要是包含了5种用药的随机对照实验: 1)单用多非利特,2)联用与不联用多非利特,3)联用与不联用多非利特的利多卡因,4)联用与不联用地尔硫卓的莫西沙星和5)安慰剂。在五个治疗周期中,受试者每天服用三次药物,并记录500赫兹的连续心电图。这样的工作在前几天写的ESC2021的工作很像,只是这个工作无论从数据还是工作上都不如那篇设置的好,最后附上文章的pipeline图(着实不太行):
2021年10月10日
Artificial Intelligence–Enabled Assessment of the Heart Rate Corrected QT Interval Using a Mobile Electrocardiogram Device
Circulation 2021 作者利用神经网络从ECG信号中估计QT间期的长度。一共有25万例病人训练,10万人测试,18万人做验证,是一个很大的队列研究。输入的ECG有标准的12导联心电图,也有移动端测量到的心电图。是一个大数据,有硬件特色的研究,但从方法学上讲,只是实现了对QT的估计,这件事本身并不够难。网络结构用了Resnet。文章里ECG信号只有10秒,所以label定义为一个样本测得所有QT间期的平均值,网络的loss既有与真实QT值的回归loss,又有交叉熵loss用于计算输出的概率,还有一项正则项,用来减少估计概率的方差,输出如下所示:
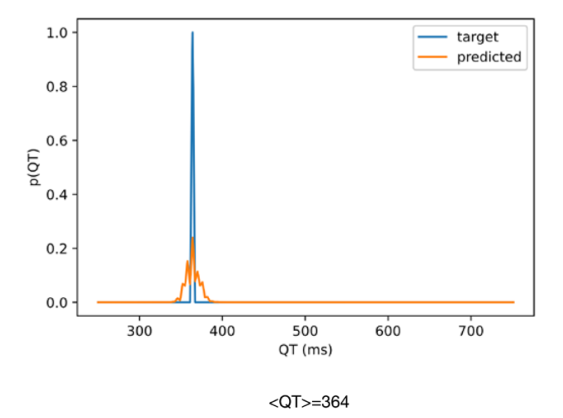
结果自然是估计的非常准,ROC在0.9左右,并且发现神经网络可以在12导联和2导联设备上都学的很好。因为之前看到用小波变换做QT识别的,我觉得用神经网络做这种信号识别的,有点蹭热度的嫌疑。能发在circulation上我觉得主要是数据比较多以及用了一个公司新型的mECG设备。
对于工作的意义,作者说“使用ai支持的mECG在配发已知的QTc延长处方前进行药室内QTc抽查,或促进门诊患者使用已知的QTc延长药物(如在相对低风险患者中使用多非利特),不仅有能力减少多病和遗传易感个体的药物相关不良事件/QTc,而且有能力减少医疗和卫生保健费用”。
2021年10月11日
今天是关于长QT综合征与尖端扭转型的特刊。
心脏细胞在一开始是极化的,在动作电位时进行了去极化,然后再复极化。
室性心动过速是指心率≥120次/分、≥3个连续的室性搏动。症状取决于发作的时限而有不同,可表现为无症状、心悸、血流动力学紊乱甚至死亡。诊断依据心电图。比短暂略长的室性心动过速,其治疗是用心脏电复律还是抗心律失常药,取决于症状。如果必要,长期治疗可采用植入性心脏复律除颤器。
不应期又称不应性(乏兴奋性,反拗期)指心脏传导系统和普通心肌组织发生动作电位之后的一段时间内,完全地或部分地丧失兴奋性的特性。每个动作电位之后是一个不应期(性) ,可以分为一个绝对不应期(性) ,在此期间不可能激发另一个动作电位,然后是一个相对不应期(性) ,在此期间需要一个比平常更强的刺激。这两个不应期是由钠和钾离子通道分子状态的变化引起的。当钠离子通道在动作电位之后关闭时,会进入一种“失活”状态,在这种状态下,不管膜电位如何,钠离子通道都不能被打开,这就产生了绝对不应期(性)。即使有足够数量的钠离子通道已经过渡到它们的静息状态,仍然经常发生一小部分的钾离子通道仍然是开放的,这使得膜电位很难去极化,从而导致相对的不应期(性)。因为钾离子通道的密度和亚型在不同类型的神经元之间可能有很大的差异,相对的不应期(性)的持续时间是高度可变的。
动作电位的过程可分为上升期、峰值期、下降期、下冲期和不应期(性)。在上升阶段,膜电位去极化(变得更加积极)。退极化停止的点称为峰值相位。在这个阶段,膜电位达到了最大值。在这之后,有一个下降的阶段。在这个阶段,膜电位变得更加消极,回到了静息电位。下极化或后超极化阶段是膜电位暂时变得比静止时更加负极化的时期(超极化)。最后,不可能或难以触发随后的动作电位的时间被称为不应期(性) ,它可能与其他阶段重叠


QT间期延长引发TdP的主要原因是两个:折返和早后除极EAD。 现在观点认为,早期后除极可能是复极不均一的原因,而折返是TdP维持的机制
QT间期反映了心室的除极和复极。影响除极的因素 (如INa通道的阻断)可影响心室除极,延长QRS时长,延长 QT间期。而从J点到T波终点的JT段反映了心室复极,对于 QT间期长度的影响更大。 IK对于心室复极具有重要意义。根 据激活速度,可将其分为快速延迟整流钾电流( IKr)和缓慢 延迟整流钾电流( IKs)。当IK由于某种因素而减弱,心室复 极时间即延长,表现为QT间期延长。在此情况下,内向电 流即可能触发新的心室除极,引发室性心律失常。通常认 为,TdP的发生与早后除极密切相关,即由于L型钙通道或 钠通道开放,和(或)细胞内外的钠钙交换,产生内向电 流并使跨膜电位达到阈电位水平,心室肌发生一次新的除极。当早后除极强度超过阈值,且发生的范围达到一定程 度,即可产生异位搏动。通常,由于其他钾电流的代偿作 用, IKs的异常并不会引发TdP,而IKr的阻断则会导致QT间期延长和TdP发生[2]。
为什么会发生早期后除极?→因为发生了QT间期延长,导致复极化还没做完,新的除极信号就来了。那为什么会发生QT间期延长?→心肌复极主要依靠钾离子的外流。 其中负责该 过程的两个主要的钾离子通道包括快钾通道($I_{K_r}$) 和慢钾通道($I_{K_s}$)。 这两种离子通道有着不同的激活和失活特性,对阻断剂和儿茶酚胺的敏感性亦有所不同。 药物导致的获得性 LQTS 的产生是由于药 物对 $I_{K_r}$通道的阻断,导致动作电位 3 期快速复极延迟,表现为QT间期延长.
那发生了后除极之后,什么是折返?为什么又会发生折返?
折返是最常见的心律失常机制,指所有基于心脏电环路发生的心律失常(图 5)。折返机制主要涉及以下两点:
●同时存在不应期/恢复期不等的快、慢传导
●围绕固定或功能性核心形成环路
折返的发生有赖于折返路径内形成单向阻滞,使环路的一支向前传导电冲动,另一支阻断传导。折返路径可以是固定的解剖环路,如心肌瘢痕;也可以是功能性环路,例如处于除极或不应状态而无法支持传导的组织区。
为什么会发生折返?→因为在心肌中间有M细胞发生了早期后除极-触发活动,从而和心肌两侧细胞无法同步→为什么是M细胞会发生这件事,什么是M细胞?→M细胞存在于心外膜下深层到心心内膜下层之间,是一种特殊类型的细胞。左室游离壁中至少有40%的M细胞。其电生理特性介于普通心肌和心脏特殊传导系统之间,与普肯野纤维最大区别是其不存在4相自动除极。离子通道受到谁的控制?→ 心肌$I_{K_r}$由hERG通道控制,因而hERG的基因缺陷,或药物阻断hERG通道,均可导致长QT综合征。

后除极是指心肌细胞的异常去极化,这种去极化干扰了心脏动作电位的第二、第三或第四心脏电传导系统。后除极可能导致心律失常。
hERG (the human Ether-à-go-go-Related Gene),是指基因KCNH2。该基因编码的蛋白质被称为 Kv11.1,是钾离子通道(英语:potassium ion channel)的α亚基(英语:alpha subunit)。该基因编码的钾离子通道(有时简单地使用'hERG'表示)最为著名的是其对心脏的电位活性,可协调心跳(即,hERG通道介导在心脏动作电位中延迟整流钾电流--IKr的复极化)。当这个通道介导电流通过细胞膜的能力受到抑制或妥协让步时,不论是由于药物的作用还是某些家族的基因突变引发,[1],都会导致潜在的致命疾病——QT间期延长综合症。
心律失常后会导致血流动力学出现问题,基本表现就是身体各器官供血不足,非常危险。
2021年10月12日
CMAME 2019 Machine learning in drug development: Characterizing the effect of 30 drugs on the QT interval using Gaussian process regression, sensitivity analysis, and uncertainty quantification 一个基于计算机仿真模型和机器学习算法估计药物后QT间期影响的方法。Method的总览如下:
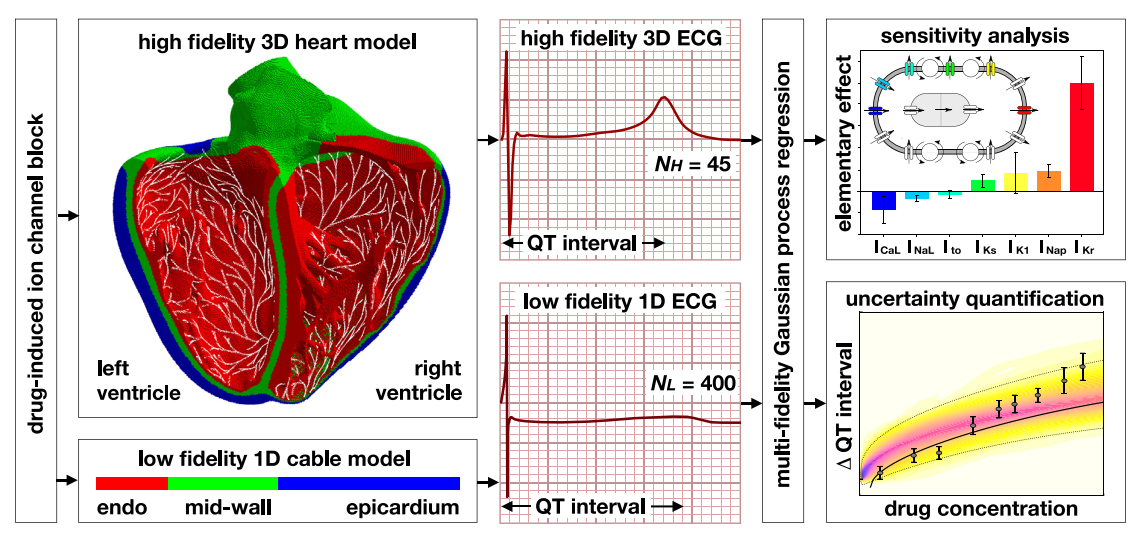
模型的输入是通过单细胞膜片钳电生理学得到的一个序列数据,记录了用药后各个离子通道的变化。之后作者首先利用这些数据在他们自己的高保真和低保真模型上模拟出来QT间期的长度,作为模型的label。作者用了高斯过程回归作为机器学习模型,其输入是7个离子通道被阻塞的分数,输出是模型计算出的QT间期长度。为什么还需要在已经模拟得到了QT间期后还要再用机器学习模型呢?我的理解是
- 模型只能仿真出一个具体的数值,但是实际的数据会存在不确定性,这需要类似高斯过程模型来进行限制
- 计算复杂度和输入的要求都比较低,作者提到了高保真模型的计算复杂度很高
- 由于输出是高保真的数学模型以及低保真模型的结果的整合,所以机器学习模型相当于学到了这两个模型的整合。
2021年10月13日
An explainable algorithm for detecting drug-induced QT-prolongation at risk of torsades de pointes (TdP) regardless of heart rate and T-wave morphology
Computers in Biology and Medicine 2021 看标题以为是可解释性的机器学习,并且预测的还是TdP的风险,其实不然。作者利用Physionet上公开的数据集(ECG Effects of Ranolazine, Dofetilide, Verapamil, and Quinidine,这个数据集不知道养活了多少人,很有可能也要养活我了)做QT间期的检测,只不过作者先批判了世界上所有的QT间期检测算法,说他们不够稳定,效果也不好。然后作者提出了通过衡量可视化的复极化时间来判断QT间期是否延长,而QT区间延长到一个临界值,作者就认为他有发生TdP的风险,换句话说,作者模型的输出还是长QT潜在风险的评估,并没有实际上衡量发生TdP的风险。
作者具体的方法是计算不通时间段的长度,简单来说就是作者首先按照时间把信号分为彩虹色,然后统计每个彩虹色下的AUC,这样就可以认为得到了T波的形态信息,然后他发现LQT和Normal病人的彩虹色比例是不一样的。A是正常人的,B是LQT的。
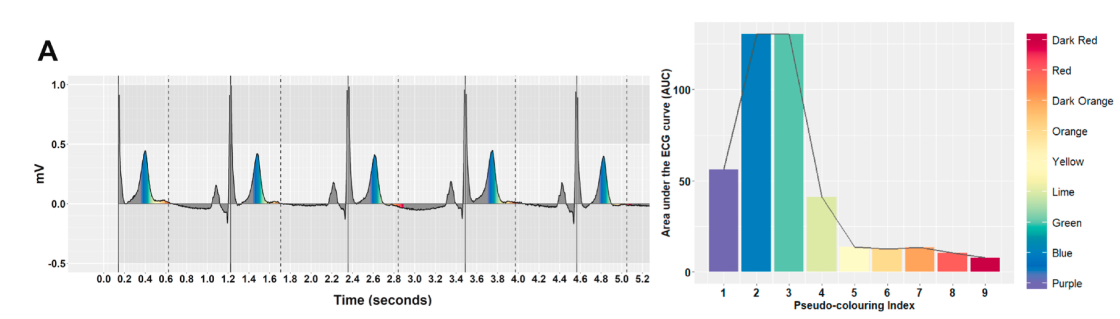
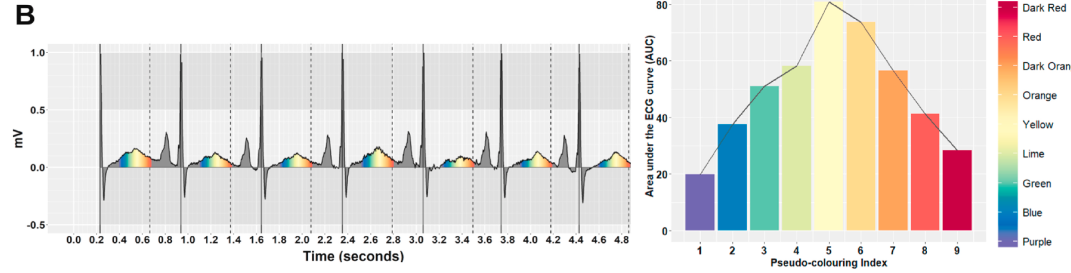
然后根据光谱颜色信息,作者进一步用了一个决策树来判断是否正常。总的来说这个光谱还是挺有意思的。
2021年10月14日
PyTorch Tabular: A Framework for Deep Learning with Tabular Data
2021 今天读一个水文,主要是介绍Pytorch包的。表格数据一直是深度学习解决的不太好的地方,有一种说法是表格数据特征之间的含义相差比较大,更适合做类似用GBT来做决策面,而神经网络是根据单组数据学习分类面,没法直接学到简单的划分方式。但近几年来,也有一些网络利用attention模仿树结构达到了SOTA的效果,所以文章就提出了一个工具包把这些模型都囊括进来,主要的模型有:
- Neural Oblivious Decision Ensembles (NODE):一种利用“ Neural equivalent of Oblivious Tree”建造网络的模型,比GBDT效果好
- TabNet:一种利用了attention机制加上mask模拟决策树的模型
- AutoInt:看作者介绍是一种应对稀疏特征非常有效的模型
通过这篇文章的指路,接下来要看看具体每篇文章的工作了。对于这个包本身,利用了Pytorch lighting的框架,将数据,模型设置都简化了,但还是需要一定的学习成本。此外,目前还不支持多类的判别。附上工具包的地址manujosephv/pytorch_tabular: A standard framework for modelling Deep Learning Models for tabular data (github.com)
2021年10月15日
TabNet: Attentive Interpretable Tabular Learning
AAAI 2021 深度学习在NLP和影像上大获成功,但是在表格类比赛中,XGboost等梯度提升树还是冠军。作者认为这主要是由于他们擅长划定表格之间的界限以及善于找到影响最大的特征。基于此,作者提出了一种借鉴了树思想的深度学习模型,简单来说就是每一步作者利用Mask对特征做一下样本层面的筛选,筛选完后作为输出的一部分;接着样本又会继续送入下一个特征提取block里。TabNet的模型如下所示:
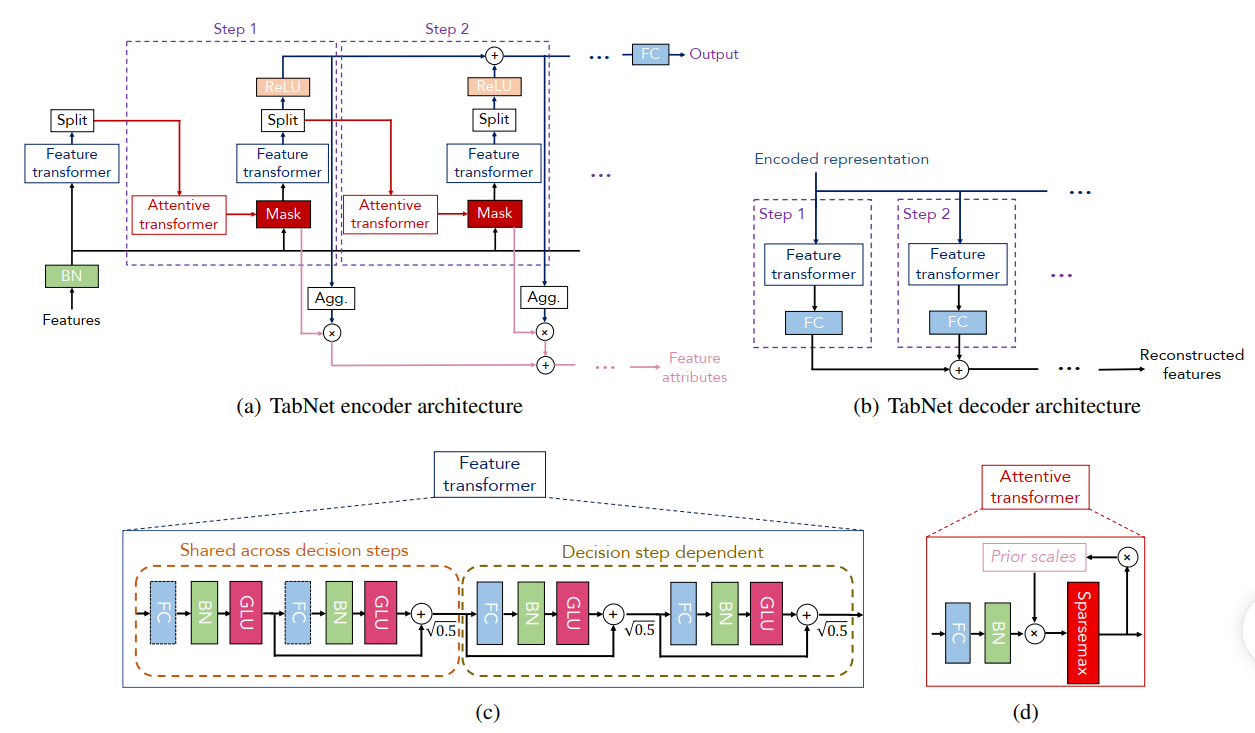
鉴于网上已经有很多文章说模型的细节,而细节也与PaperFlash的思路不符,这里简单记录一下Encoder的流程:数据先进行BN,然后送到Feature Transformer中进行一些变换,对于变换后的结果一部分通过Relu作为输出,另一部分送入Attention Transformer里生成instance level的Mask,这部分的Mask会重新作用于输入数据,得到新的特征筛选,筛选后的数据再送到下一个Encoder中进行计算。最后每个block里的输出及合起来通过MLP就得到了最终的结果,而所有的Mask也会经过操作得到一个特征的贡献度。
实际上,我在一些表格数据上进行测试,效果并没有XGboost好,F1 score普遍都差了0.03,Kaggle上也有很多人在吐槽这个模型的效果并不好。我的感觉是网络设计挺有新意的,但是中间貌似有太多trick了,不是很好解释。

文章评论